







Парсинг (от англ. parse — «анализ», «разбор») — автоматизированное получение информации с веб-сайтов с помощью программ, которые называются парсерами. Парсеры автоматически собирают и систематизируют определённый контент с веб-страниц, документов, API или даже исходного кода.
Что такое парсинг веб-страниц
Простыми словами парсинг веб-страниц — это автоматическое сканирование выбранных сайтов с задачей найти и вытащить нужную информацию и представить в виде таблицы или другого удобного сводного файла.
Парсинг — это полезная штука, которая пригодится каждому маркетологу. С помощью парсинга можно получить разные сведения под любые задачи, например, для изучения конкурентов или свежих трендов в вашей сфере, причём быстро и на больших данных.
Если дополнить картину данными сквозной аналитики о поведении собственных клиентов, например, количестве продаж, результатах сделок, бюджетах и эффективных каналах продвижения, то в сумме мы получим ценнейшие инсайты, основанные на точных данных.
Как работает парсинг
Представьте, что у вас есть огромная газета, и вы хотите выписать оттуда только телефоны или только названия компаний.
Парсинг работает как ножницы и маркер:
- ножницы вырезают из текста куски, которые вам нужны;
- маркер подсвечивает нужные данные, так что мы видим только выделенные фрагменты.
Вместо того чтобы читать и переписывать руками, программа делает это автоматически — по заданным правилам.
Что можно парсить и зачем это нужно
Инструмент имеет широкий круг применения. Парсинг можно использовать для анализа различных типов контента с веб-сайтов, включая:
🏷 цены на продукты и карточки товаров (например, копируют описание товара на английском языке, а затем переводят на русский и размещают на своем сайте),
😎 сведения о конкурентах,
😊 отзывы клиентов,
📰 новостные статьи,
📶 контент в социальных сетях,
🧍аудитории групп в соцсетях,
🔎 частоту поисковых запросов (парсинг выдачи),
🔧 популярные заголовки и связанные ключевые слова.
Маркетологи могут использовать эти сведения для исследования рынка, управления и корректировки маркетинговых стратегий и выбора рекламных площадок.
А затем на основе полученных материалов выстраивать тактику продвижения компании в сети, чтобы:
👍 предложить клиентам самые выгодные цены,
😉 лучше отстроиться от конкурентов,
💡 настроить SEO-оптимизацию и рекламные кампании в поисковых системах,
💪 вести SERM (Search Engine Reputation Management — направление в репутационном маркетинге) и следить за рейтингом бренда в сети,
❤️ соответствовать запросам аудитории.
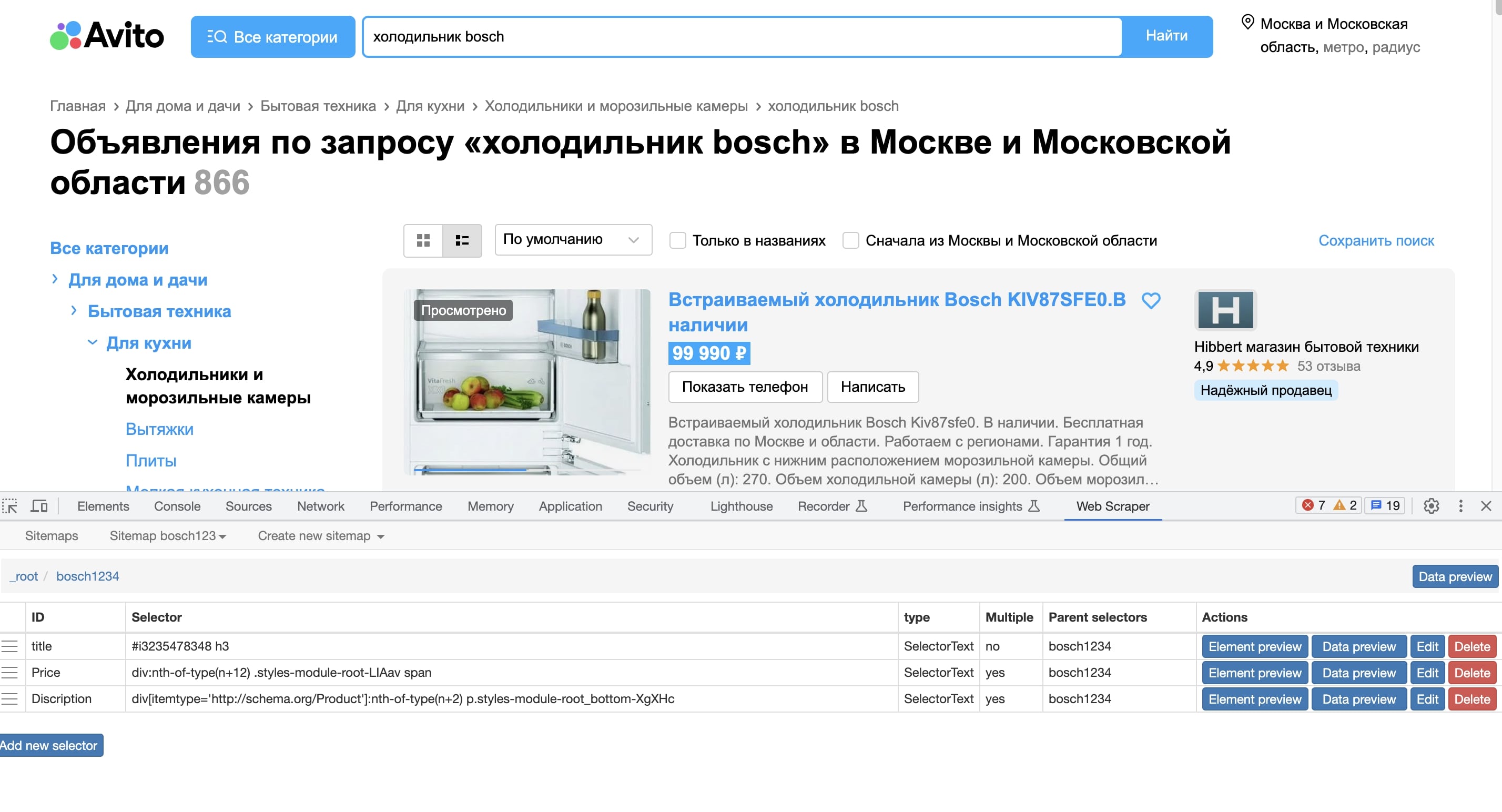
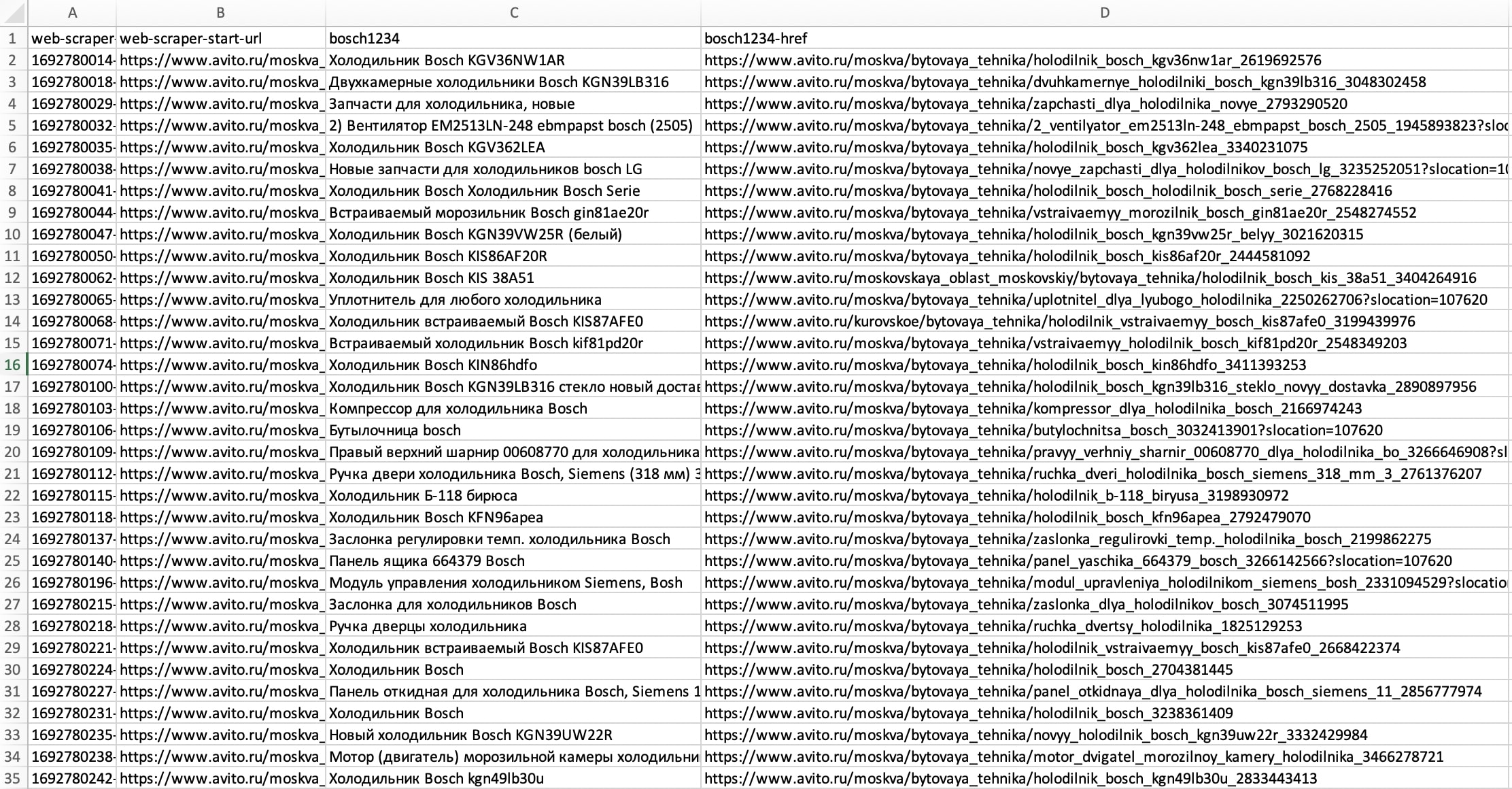
Благодаря парсингу можно за короткое время найти кучу полезной информации и собрать её в формат XLSX. Данные собираются и систематизируются в зависимости от заданных настроек.
Зачем маркетологу парсинг данных
- Анализ конкурентов
Маркетологи могут выполнять сбор информации о чужих продуктах и рекламных стратегиях по заданным критериям, и смотреть на них с точки зрения развития своей компании, а значит всегда запускать более эффективные рекламные кампании.
- Агрегация контента
Помогает собирать релевантные статьи, сообщения в блогах, новости, чтобы далее использовать их в работе со своей аудиторией, тем самым находить интересные темы и улучшать контент-маркетинг. Например, для запуска email-рассылок, которые будут интересны целевой аудитории.
- Мониторинг цен
Позволяет отслеживать изменения стоимости регулярно или в режиме реального времени, чтобы соответствующим образом корректировать ценовую политику.
- Генерация потенциальных клиентов
Маркетолог сможет извлекать контактную информацию, такую как адреса электронной почты и номера телефонов для создания списков потенциальных клиентов.
Полученные вводные можно складывать в гугл-док или в заметки, а можно с помощью специального html-плагина разбирать веб-страницы на части в Фигме. Такой анализ помогает собрать свой лендинг, например, Marquiz Pages.
- Получение информации для SWOT-анализа
В рамках SWOT-анализа (анализа сильных и слабых сторон, возможностей и угроз) важно иметь актуальные и достоверные сведения. Как правило, парсер автоматически собирает фактуру из различных источников. Например, информацию о конкурентах, ценах, отзывы клиентов и другие виды контента, которые тоже могут быть полезны для SWOT-анализа.

Экспресс-анализ по SWOT в сфере инфобизнеса
Популярные вопросы про парсинг
Как парсеры могут помочь в контент-маркетинге?
- Сбор идей и тем. Парсер вытащит заголовки, теги и популярные материалы у конкурентов — быстро видно, что работает.
- Контент-анализ. Парсер помогает анализировать, какие вопросы закрывают конкуренты, чего не хватает — и писать полезные материалы под эти пробелы.
- Отслеживание трендов и отзывов. Парсить упоминания бренда, отзывы и комментарии — и находить боли и кейсы для новых статей.
- Автогенерация фидов: собирать базу кейсов, цитат, данных для таблиц и вставлять в шаблоны постов и писем. Пример: парсер собирает 100 заголовков из нишевых блогов за неделю — вы выбираете 10 повторяющихся тем и делаете серию статей.
Что такое SERM и как парсинг может помочь в этом?
SERM (Search Engine Reputation Management) — управление репутацией в поиске: что люди видят по вашему бренду.
Роль парсинга: регулярно вытаскивать выдачу по ключевым запросам, следить за результатами поиска — сниппеты, отзывы, локальные карты, фиксировать негатив и источники.
Польза: автоматические сигналы о падении позиций, о появлении негативных статей или сырой дублированной информации — можно быстро реагировать контентом или PR.
Пример: парсер каждое утро собирает топ-10 по запросу «Компания X отзыв» и отправляет предупреждение, если появился новый негатив.
Как использовать парсинг для SWOT-анализа?
- Strengths. Парсить положительные отзывы, кейсы, уникальные фичи конкурентов.
- Weaknesses. Искать повторяющиеся жалобы, высокие цены у конкурентов, отсутствие функций.
- Opportunities. Искать пробелы в контенте, незакрытые вопросы аудитории, новые ниши по запросам.
- Threats. Мониторить прайсы конкурентов, появление новых игроков, регуляторные изменения в новостях.
Как парсинг может помочь в управлении маркетинговыми стратегиями?
- Мониторинг конкурентных активностей: цены, промо, лендинги, новые продукты —> корректировать свои кампании.
- Быстрая проверка гипотез: парсер подтянул рекламные креативы конкурентов —> тестировать контент-гипотезы.
- Автоматизация отчётности: данные в реальном времени идут в дашборд —> маркетинг быстрее принимает решения.
- Поддержка ABM/ABS: парсите новости по целевым аккаунтам (управленческие перестановки, интеграции) и реагируете персонализированными кампаниями. Пример: заметили, что у ключевого клиента меняется руководитель — запускаете цепочку сообщений, предлагающих релевантный кейс.
Какие риски связаны с парсингом веб-страниц?
- Юридические: нарушение условий использования сайта, проблемы с авторскими правами, персональные данные (GDPR и локальные правила).
- Блокировки: IP-бан, капчи, деиндексация при агрессивных запросах.
- Качество данных: дубли, устаревшая информация, шум — требуется валидация.
- Безопасность: хранение чувствительных данных требует защиты и управления доступом.
- Этика и репутация: агрессивный парсинг может навредить отношениям с партнёрами. Рекомендация: сначала смотреть на API или договориться об интеграции; если парсить — соблюдать лимиты, robots.txt и правовые нормы.
Можно ли парсить данные с защищённых сайтов?
- Технически — да, но с оговорками: защищённые сайты требуют авторизации (логин/пароль), иногда MFA, session cookies или специфичных заголовков. Для динамических страниц нужен headless-браузер (Puppeteer/Playwright).
- Если у вас есть учётные данные и право на использование (например, ваш аккаунт), то можно, но если вы обходите защиту без разрешения — это может быть нарушением закона и правил сайта.
Рекомендация: всегда искать официальный API или соглашение о доступе. При необходимости согласовать с владельцем сайта юридически и технически.
Как парсеры обрабатывают большие объёмы данных?
При парсинге больших объёмов важна архитектура и контроль: задачи распределяют между рабочими серверами, используют пул прокси и регулируют скорость запросов, чтобы избежать блокировок и перегрузки сайтов. Собранные данные быстро очищают и нормализуют, сохраняют в структурированные хранилища и анализируют — при необходимости с помощью автоматической обработки (кластеризация, извлечение сущностей, анализ тональности), чтобы получить готовые инсайты.
Законность парсинга
Законность сбора информации с веб-страниц зависит от целей сбора и условий их дальнейшего использования.
Хотя обычно парсинг в интернете является плюс-минус общепринятым (парсят практически все поисковики от Internet Explorer до Яндекса), анализ конфиденциальных личных данных или материалов, защищённых авторским правом, прямо запрещён.
❗ Необходимо соблюдать законодательство в сфере обработки данных и обеспечивать соблюдение правовых норм. В противном случае первый же владелец сайта, с которого парсят, может потерпеть убытки из-за дополнительной нагрузки на ресурс, если скликивание будет похоже на DDOS-атаку. Так парсить как минимум неправильно.
Как парсить законно?
| ✅ Можно | ❌ Нельзя |
| Проанализировать собственный сайт для поиска ошибок, неработающих страниц, битых ссылок и других технических проблем | Полностью копировать чужой контент |
| Анализировать сайты конкурентов по ценам, заголовкам, описаниям товаров и услуг | Организовывать DDOS-атаки (Distributed Denial of Service attack) |
| Собирать открытые данные о пользователях в соцсетях | Собирать сведения из личных кабинетов пользователей |
На какие законы стоит обратить внимание, чтобы знать, какие есть ограничения по сбору данных:
— ФЗ «О персональных данных» от 27.07.2006 N 152-ФЗ
— ГК РФ Статья 1259. «Объекты авторских прав»
— ГК РФ Статья 1260. «Переводы, иные производные произведения. Составные произведения»
— ГК РФ Статья 1335.1. «Действия, не являющиеся нарушением исключительного права изготовителя базы данных»
— УК РФ Статья 272. «Неправомерный доступ к компьютерной информации»
— УК РФ Статья 273. «Создание, использование и распространение вредоносных компьютерных программ»
— УК РФ Статья 146. «Нарушение авторских и смежных прав»
💡 Полезно подробнее почитать и про европейский закон о защите персональной информации в интернете Что такое GDPR. Он касается в том числе российских компаний
Как можно парсить
Парсят с помощью автоматизированных инструментов, таких как:
- специальные программы и расширения для тех, кто хочет искать нужную информацию самостоятельно и без программирования;
- облачные сервисы, они также не требуют программистских навыков, просты в работе и подходят для небольших компаний;
- фреймворки с готовыми алгоритмами (для тех, кто умеет программировать);
- парсеры, разработанные программистами под определённую задачу — разработка стоит дорого, и обычно такой услугой пользуются крупные сайты или площадки онлайн-торговли. В этих компаниях мониторинг цен вручную может растянуться на несколько дней, поэтому затраты на свой парсер, в общем, оправданы. При этом парсер обладает всем необходимым набором функций, которые работают с учётом всех нюансов компании.
По сравнению с ручным поиском, парсеры могут достаточно эффективно анализировать содержание веб-ресурса, просто следуя конкретным алгоритмам по заданным параметрам.
| Популярные парсеры | Название |
| Десктопные парсеры сайтов | Parsehub (бесплатный), ParserOK, ComparseR |
| Облачные серверы | Диггернаут, Apify, Mozenda (есть версия на десктопе) |
| Парсеры для социальных сетей | TargetHunter, Pepper.Ninja, Церебро Таргет |
| Бот для автоматического сбора email-адресов | Scrapebox Email Scraper |
Иногда, в качестве альтернативы, парсинг можно делать вручную путём копирования и вставки выбранного контента с веб-страниц. Работает, когда это не долго и не сложно. Однако в случае работы с большими объёмами данных автоматический поиск более эффективен. Работать должен компьютер, а человек пусть лучше занимается сложными творческими задачами и проектами.
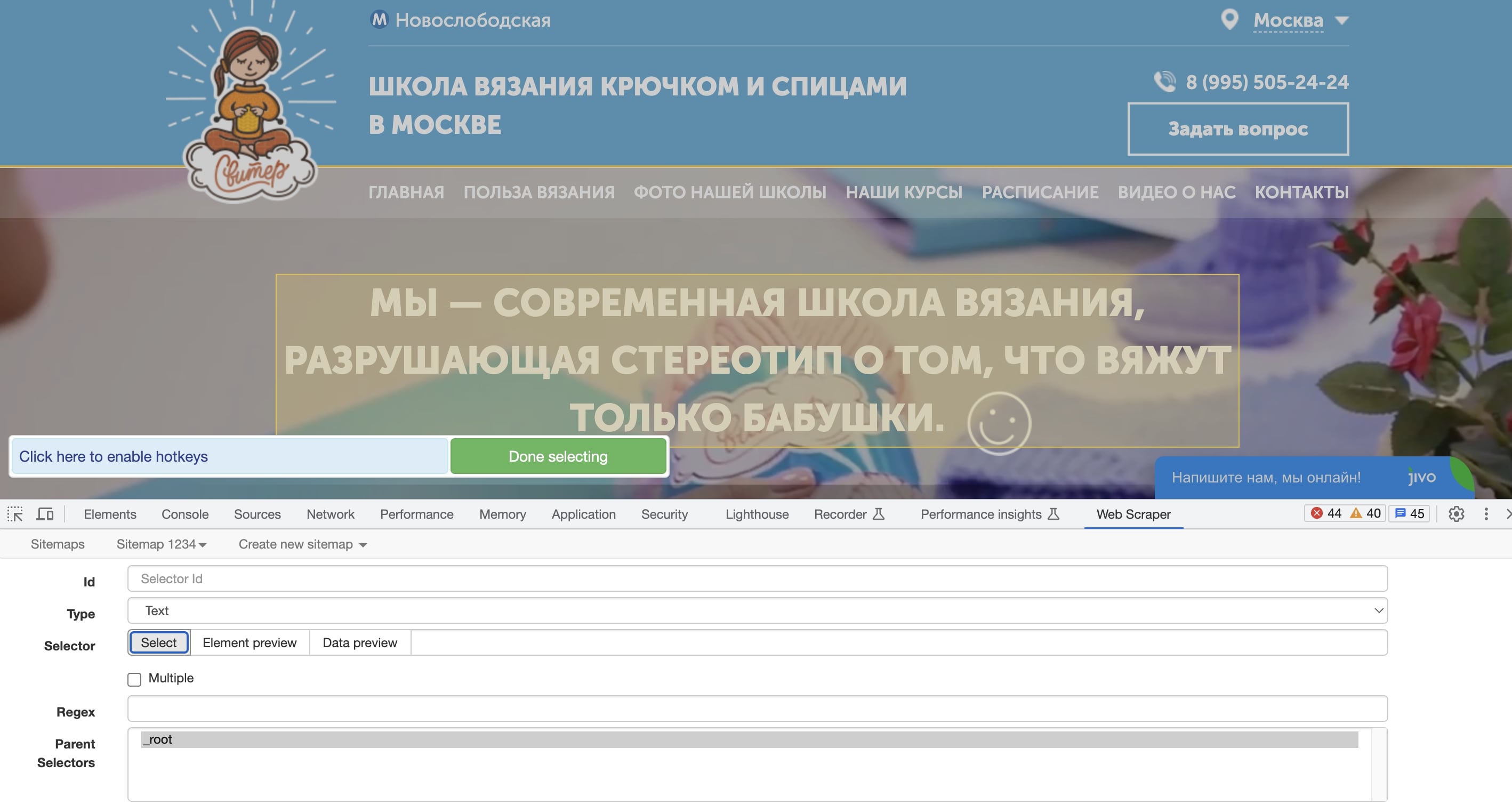 Расширение WebScraper для браузера Google Chrome: после установки легко настроить план (sitemap) движения по веб-сайту и указать материалы и теги для анализа. Парсер будет перемещаться в соответствии с настройками и искать нужную информацию
Расширение WebScraper для браузера Google Chrome: после установки легко настроить план (sitemap) движения по веб-сайту и указать материалы и теги для анализа. Парсер будет перемещаться в соответствии с настройками и искать нужную информацию
Инструменты для парсинга
Кратко, по делу и с конкретикой — какие инструменты для парсинга обычно доступны в России без VPN, как они отличаются и что учесть при выборе.
Что реально можно использовать без VPN
- Octoparse — визуальный десктоп, облачный парсер, подходит для тех, кто не хочет возиться с кодом.
- ParseHub — ещё один визуальный SaaS-парсер, удобен для страниц с динамикой.
- Web Scraper (расширение для Chrome) и Data Miner — лёгкие расширения для быстрых задач, не требуют отдельного сервера. Их удобно запускать локально в браузере.
- «Облачный парсер» и ParseBigData— чаще всего работают без VPN и дают форматы выгрузки под локальные маркетплейсы. Подойдут, если нужна совместимость с российскими сервисами и поддержка локальных форматов.
Когда и почему придётся подключать дополнительные сервисы
Для стабильного массового парсинга почти всегда нужны прокси-серверы и решения по обходу анти-ботов и капч. Даже если сам инструмент доступен, без прокси можно быстро упереться в блокировки и лимиты.
Простыми словами — прокси-сервер это посредник между вашим устройством и интернетом. Когда вы что-то запрашиваете (страницу, файл, API), запрос сначала идёт на прокси, а прокси уже обращается к нужному сайту и пересылает ответ вам.
Представьте почтовый офис. Вы хотите отправить письмо, но не хотите, чтобы получатель видел ваш адрес. Вы отдаёте письмо на почте, почта пересылает его от своего адреса и привозит ответ обратно. Прокси работает так же — сайт видит адрес прокси, а не ваш. Чтобы избежать блокировок прокси меняет IP, это называется «ротация прокси».
Недорогие прокси-серверы можно купить на определённый срок, от одной недели до 3 месяцев обычно хватает, чтобы напарсить всё, что нужно. Например, PX6.me или ProxyLine.
Разница между прокси и VPN:
- Прокси обычно работает для одного приложения или протокола (например, браузера) и может не шифровать трафик.
- VPN поднимает виртуальную сеть и шифрует весь интернет-трафик с устройства Прокси это маска для отдельных запросов, VPN это тоннель для всего трафика.
Категории инструментов и когда их брать
- Лёгкие задачи или разовые выгрузки: подойдёт Web Scraper (Chrome), Data Miner — запускаете в браузере, не нужен сервер.
- Регулярный сбор без кода: Octoparse, ParseHub — удобны для автоматизации и экспорта в форматы CSV, XLSX, JSON.
- Масштабный, анти-бот: платные прокси + сервисы типа Bright Data, Scraper API, специализированные провайдеры (обратите внимание, что у таких провайдеров — отдельные условия доступа и стоимость).
- Локальные решения и интеграции: российские облачные парсеры и кастомные парсеры (под Яндекс. Маркет, Tiu и прочие) — удобны, если нужна выгрузка под российские площадки.
Быстрая рекомендация по безопасности и праву
- Всегда проверяйте robots.txt и лицензионные условия целевого сайта.
- Для больших объёмов используйте платные прокси и контролируйте частоту запросов — это снижает риск блокировок и юридических проблем.
Чтобы погрузиться в пучины парсинга понадобится изучить язык программирования Python.
Какие типы данных можно парсить с сайтов
Для анализа доступны один или несколько отдельных элементов. Вот некоторые примеры:
- текст и заголовки: содержимое заголовков, статей, новостей, описание продуктов (полезно для контекстной рекламы);
- изображения: URL изображений, их описание, размеры;
- ссылки и адреса: ссылки на другие веб-ресурсы, внутренние страницы, даже файлы для загрузки;
- таблицы: стоимость, характеристики продуктов, описание, каталоги и т. д.;
- цены и денежные единицы: стоимость, валютные курсы и сведения о других денежных единицах;
- популярный мультимедийный контент: видео, аудио и другие медиафайлы;
- показатели социальных медиа: лайки, комментарии, портрет пользователей;
- отзывы и оценки: отзывы и рейтинги пользователей о продуктах или контенте;
- география: адреса, координаты и другие геолокационные сведения;
- акции и скидки у конкурентов: сезонные акции, скидки и специальные предложения онлайн-магазинов.
Заключение
Парсинг — ценный инструмент для маркетологов по сбору и анализу контента с веб-страниц. Этот процесс, проще говоря, помогает сделать маркетинг более эффективным и удобным, особенно когда речь идёт об обработке большого объёма информации. Это позволяет принимать обоснованные решения, оставаться конкурентоспособными и хорошо адаптировать свои стратегии к постоянно меняющемуся рыночному ландшафту. Плюс к этому даже обычный бесплатный парсер способен значительно разгрузить сотрудников.
Тем не менее, важно нести ответственность за правильную обработку данных и работать с полученными материалами с соблюдением правовых и этических стандартов. Не должно возникать спорных моментов, касающихся злоупотребления при использовании данных.














